|
Identify Docs
Batch Process Tiff Images to Bates Stamped PDF's
Create Text Searchable PDF's
Text Searchable Tiff Images or Text files
Ideal for processing entire
CD's of Images or Output from a Copier
What it does:
-
Identify Docs offers three processing modes,
single document, batch process with user input, silently batch
process
-
OCR’s Tiff Images with three
forms of output, a text file, text searchable Tiff, or text
searchable PDF
-
Stamps PDF Output with
identifying information, such as number in a series and page
number of document and more
-
Adds meta data to PDF output
What it does not do:
-
Identify Docs does not preserve
any OCR formatting at all. The output is for research, not for
converting image files into files that can be edited.
-
Run without Microsoft’s Document
Imaging – a component of Microsoft's Office Suite
Initial Design Concept:
The initial design when developing Identify Docs was to create an
affordable, easy to use software package for attorneys that would
allow them to process in house a CD full of Tiff images. The
processing would include performing Optical Character Recognition on
the image and stamping the image with identifying information (Bates
Stamping), without obscuring any part of the image. The final
product does that and more.
Ease of Use:
Identify Docs is easy to setup and
use. The user opens a file or selects a folder (if batch processing)
and fills out a one page form of settings. These settings can be
saved in the output folder for use with all documents that pertain
to that job or set as a default for all documents.
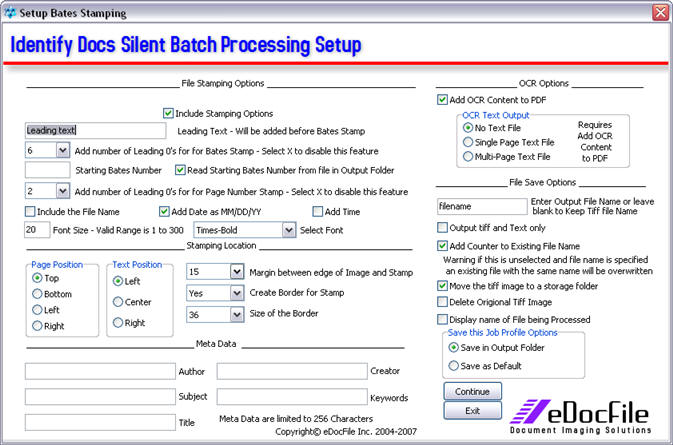
OCR Function:
Identify Docs works in conjunction with Microsoft’s Document Imaging
which contains one of the best OCR engines on the market. It uses
this engine to process the Tiff images into Searchable Tiff Images,
Text Searchable PDF Images or a Text File. The text file can be a
multi-page document (if processing multi-page tiffs) or a series of
single page tiff files named the same as the document with a counter
placed at the end of the file name. Please note that when creating
text searchable PDF's the text will be placed on the page but not
aligned with the image.
Stamping Options:
When outputting to a PDF, Identify
Docs has the ability to stamp the image with identifying data. It
can place up to 85 characters on the image including a short note
(case number or project name), file name, page in a series, page
number in the document and date and time entered. These settings can
be saved for later use so as new documents arrive the user does not
have to
look up where they left off.
The stamp can be placed on any side of the page with any alignment
desired. It can be on the top, bottom, left side or right side of
the document with alignment of left, right or centered. It can also
be placed on a border, assuring that it will never obscure data on
the image.
Processing Methods:
The processing method can be done in
three ways, a single document at a time, in a batch process, or in a
silent running batch process.
-
A single document at a time is
designed for use with a copier that scans to a file folder on a
network. The user opens the tiff image with Microsoft’s Document
Imaging and then opens Identify Docs. The user is prompted for
an output folder and the document is processed using settings
contained in the output folder. These rules contain, the file
numbering, file naming, position of the stamp, text file output
if desired, and meta data.
-
The batch processing method is
similar to the single document processing, only it assumes that
all the documents in a folder are going to be placed in the same
output folder. This allows a user to scan in numerous files,
quickly review them, and add meta data to them if desired. This
is ideal for processing numerous files scanned with a copier or
files received on a CD, where they need to be reviewed before
entering the system.
-
The silent batch processing
method is the most powerful method of operation. It will look at
a root file folder and process silently all the documents in the
folder and its subfolders. This allows a user who receives a
disk of tiff images to simply copy all the images on the CD to a
file folder on their PC, run the program and then search for any
words in any of the documents. It can also be used to duplicate
a file folder structure of tiff images with one of Text
Searchable PDF Images.
Speed:
Each document type is different as to
the size and contents so the output speed will vary. On average our
tests showed a speed of 4 seconds per page on a random sample. This
equates to 900 pages per hour on average, there is no guarantee that
the end user will achieve this speed on their documents.
Meta Data:
The user can enter up to 256
characters in the Author, Subject, Title, Keywords and Creator
fields. By default the producer will be set to the Licensee of the
software. The meta data can be set by default for all documents in a
folder or the user can be prompted each time a document is added if
using the single document method or batch processing method. Being
prompted for meta data is not available in the silent processing
method.
File Naming:
The user can keep the original file
name, be prompted for a file name each time a document is added if
using the single document method or batch processing method, or
assign a file name for use with all documents in the job. It using
the same file name for all document in a job, a counter will be
placed at the end of the file name assuring the user no existing
document is overwritten. The counter will be the beginning page
number in the series not file-1pdf, file-2.pdf, file-3.pdf etc. If
using multi-page documents where file 1 is 10 pages, file 2 is
15 pages and file three is 20 pages the files would be file1-pdf,
file11-pdf, file26-pdf and file47-pdf.
Folder Output:
All the files can be output to a
single file folder or a folder system matching the folder structure
that the documents came from. If output is to be to a single file
folder from documents contained in a hierarchal folder structure it
is important to use the file numbering option. If it is not used and
two files exist with the same name the existing one will be
overwritten.
The Original File:
Once processed, the original tiff
file will have an invisible layer of OCR text on it. This file can
be automatically moved into a subfolder of the output folder
allowing the file to be processed again if the numbering is to be
changed. If the files are going to be distributed to someone else
and the OCR layer of text is not desirable they need to be copied
somewhere else before processing.
Searching for documents:
The user needs to search for
documents based on the output format selected. The text searchable
tiffs can be searched for with the search engine built into windows.
The text searchable PDFs can be searched for with Acrobat or the
search engine in Windows provided that the ifilter from Adobe has
been installed. The ifilter for PDF's can be found on Adobe's
Website
Although Text
Searchable Tiffs and PDF's can be searched for with the search engine built
into Window, if more search options are desired or if retrieval
speed is critical eDocfile recommends dtSearch. It will search not only the
PDF's and Text Searchable Tiffs but also, most all other document
types including, Outlook Mail, Word Documents, Excel
Spreadsheets etc. It allows the user to refine the search by Proximity
“words within so many words of another”, Stemming (the root of the
search word), Synonym (related words) Phonic (sound like) and Fuzzy
Searching (some of the letters match). It can also limit the
search by index data in the Author, Subject, Title and Keywords in a
files properties. It does the searching almost instantaneous, unlike
the search engine in Windows.
If searching for the Bates Stamped PDF's with dtSearch select the
option "View PDF Files as plain text" in the
preferences section of the Options Menu of dtSearch. This will allow
the text to be displayed that is contained in the PDF, making it
quicker to cycle through the documents, as Acrobat does not have to
open each time a user selects a different option. If searching Text
Searchable Tiffs, dtSearch can also be used the same way. By default
dtSearch is currently not setup to search tiff images. To change the
settings in dtSearch to include Text Searchable Tiffs
click here. To learn
more about dtSearch
click here.
Support:
Don't hesitate to call us. If
necessary we will remotely access your PC and setup your first job
for you.
Trial Version of Identify Docs:
The trial version has full functions
and is limited to 15 files being processed. It can be
downloaded here.
|
Ordering:
All orders are placed through PayPal and
software is download only.
Your key will arrive within 24 hours for
faster service
call eDocFile at 813-298-2474.
Identify Docs |
| Single Copy $299.00
|
Two Copies $499.00
|
Five Copies
$999.00
|
Site License
$1999.00
|
|
|
|
|
"Note:
Pricing is non-concurrent. A 5-user purchase means a license for 5
seats. Pricing also works as volume licensing. For example, a
100-user purchase could be for 100 laptops."
Contact us
directly for discounts on higher volumes or other dtSearch Products
Contact us for more info

| 